En cybersécurité, il existe de nombreux "termes consacrés" qui sont difficilement traduisibles.
Même en faisant attention à en employer le moins possible, tout(e) expert(e) en cybersécurité lancé(e) dans l'explication d'un sujet un peu touffu, finira par en utiliser quelques uns.
Pour ses interlocuteurs, impossible de pleinement comprendre le propos sans avoir saisi le sens de ces termes.
Que feront-ils ?
Interrompre l'expert pour lui demander de définir les termes spécifiques ? Au bout de la troisième fois, ça risque de sacrément casser le rythme.
Taper discrètement le mot sur Google pour trouver la définition du terme pendant que l'expert continue de parler ?
PADBOL !
Ces termes sont souvent assez difficiles à expliquer en quelques mots. Si vous tombez sur une définition en une ligne, elle comportera très probablement encore plus d'autres mots que vous ignorez.

Donc ce qui arrivera probablement sera un acquiescement poli... en ayant perdu le fil il y a 20 minutes.

Sauf que si l'on veut que les journalistes, politiques, décideurs, chefs d'entreprise, etc. comprennent mieux la cybersécurité et ses enjeux, il va bien falloir rendre ce jargon compréhensible par le tout venant.
Et comme on n'a pas trouvé de ressources qui fassent ça comme il faut ... et bé on va le faire nous même.
On va devoir simplifier grossièrement de temps en temps, mais ça restera utile.
Ce n'est pas trié par ordre alphabétique car comme je l'ai dit, on a besoin de définir certains termes en premier, pour en expliquer d'autres après.
Vulnérabilité / faille
«Vuln» pour les intimes, c'est un défaut, dans un programme informatique, permettant de nuire. C'est le mot poli pour « faille informatique ».
«Programme informatique» est entendu ici au sens large : une application sur votre ordinateur, un site Web, un système d'exploitation, le fonctionnement de votre téléviseur, tout ça ce sont des programmes.
- Par exemple, un programme qui a le défaut que votre image de profil apparaît tournée à 90° ... ce n'est pas une vraie nuisance, donc ce n'est pas une vulnérabilité.
- Un programme qui a le défaut que n'importe qui peut voir l'historique des positions GPS depuis lesquelles vous vous êtes connecté ... là déjà ça nuit un peu plus sérieusement, c'est une vulnérabilité.
- Un programme qui a le défaut que n'importe qui peut émettre des virements depuis votre compte en banque ... là c'est de la grosse nuisance !
Pour autant, même si les vulnérabilités sont souvent des «bugs», ce ne sont pas QUE ça.
Il y a aussi des vulnérabilités qui sont dues à des mésusages. Par exemple, utiliser le mot de passe 1234 c'est un mésusage, ce n'est pas le programme qui marche mal.
D'autres fois, ce n'est pas une question de bug ou de mésusage, c'est que n'est pas exposé à la bonne population. Par exemple le bouton rouge qui permet d'éteindre le réacteur nucléaire en cas de surchauffe, il est dans une salle dont l'accès est hautement sécurisé. S'il était dans la rue, accessible à tout le monde, le problème ne serait pas qu'il marcherait mal, le problème ne serait pas qu'on l'utilise mal, le problème serait que tout le monde puisse l'utiliser.
Point terminologie :
Quand un programme souffre d'une vulnérabilité, on dit qu'il est "affecté" par cette vulnérabilité.
Quand un pirate utilise une vulnérabilité contre un programme, on dit qu'il "exploite" cette vulnérabilité.
Par extension, on va aussi dire qu'une entreprise (ou une organisation quelconque) a des vulnérabilités. Cela signifie qu’elle utilise des outils informatiques qui, eux-même, sont vulnérables.
Pentester
(Prononcé «peinetesteur»)
Contraction de penetration tester, c’est le métier qui consiste à essayer de pénétrer dans le réseau d’une organisation en trouvant et en exploitant ses vulnérabilités.
Le but de la démarche, pour l’organisation, est de découvrir précocement ses vulnérabilités afin de les combler, avant qu’elles ne soient exploitées par un cybercriminel.
Cette démarche se nomme un «test d’intrusion».
Le pentester est donc payé par cette organisation. Il peut être un prestataire ou, plus rarement, un employé.
CVE
Acronyme de Common Vulnerabilties and Exposures.
C'est une vulnérabilité publique (donc connue de tous), publiée dans la base des CVEs. Exemple : CVE-2017-0100
La base des CVEs est une des tentatives (fructueuse celle-ci) de cataloguer les vulnérabilités connues.
Par exemple, quand Jean-Sylvain trouve une vulnérabilité dans le programme Google Chrome, où doit-il le dire ?
S'il fait une publication Facebook pour avertir ses amis, ça va être dur pour les 1 milliards d'autres utilisateurs de Chrome (qui ne sont pas amis avec lui sur Facebook) de savoir qu'ils utilisent un programme affecté par une vulnérabilité.
S'il avertit Google, peut être que Google fera une publication sur son site pour dire "attention n'utilisez plus cette version elle est vulnérable". Ou peut être qu'ils ne voudront pas le marquer car ça fait de la mauvaise pub.
Pendant une époque c'était donc un peu le Far West. Les découvreurs de vulnérabilités publiaient ça sur des forums spécialisés. Mais l'information était extrêmement éparpillée. Pour savoir si le programme que vous utilisiez était vulnérable, il aurait fallu parcourir les 10 forums spécialisés de chaque pays (autant de langues différentes) et chercher si quelqu'un parle de votre programme.
Donc depuis 2001, le MITRE (organisme américain) fait le travail de fourmi de recenser toutes les vulnérabilités connues en une seule et même place : la base des CVEs.
De nos jours, c'est LA base la plus fournie et 90% des vulnérabilités connues doivent y figurer (au doigt mouillé).
Donc quand vous avez découvert une vulnérabilité sur un programme, vous avertissez le MITRE, vous lui envoyez la démonstration, et il publie un bulletin de vulnérabilité auquel est associé un numéro de CVE. Par exemple CVE-2012-4598 est la 4598ème vulnérabilité découverte l'année 2012.
Cette base permet surtout une recherche inversée : j'utilise tel programme, dans telle version, donne moi la liste des vulnérabilités connues qui l'affectent.
Par facilité de langage, quand on dit "une CVE", on parle d'une vulnérabilité publique qui est associé à un bulletin CVE.
« Il y avait 30 CVE sur leur Apache » = ils avaient un serveur utilisant le programme Apache dans une version pour laquelle 30 vulnérabilités sont publiquement recensées.
CVSS
C'est un score sur 10 permettant de décrire la dangerosité d'une CVE.
Il y a des vulnérabilités qui ne peuvent être exploitées que par quelqu'un qui possède déjà un compte sur la cible et qui, quand elles sont exploitées, aboutissent seulement à révéler le nom des autres utilisateurs. Ce n'est pas très grave.
Inversement, il existe des vulnérabilités qui peuvent être exploitées par n'importe qui depuis Internet et qui aboutissent à ce que la cible soit entièrement compromise. C'est très grave.
Il faut donc une métrique pour juger de cette gravité (on utilise d'ailleurs plutôt le terme de «sévérité »).
La base des CVE a choisi d'utiliser un score sur 10 (1 c'est une vulnérabilité presque indolore, 10 c'en est une très grave) nommé score CVSS (pour Common Vulnerability Scoring System).
Ce score tient compte des conditions nécessaires à réussir une exploitation et des impacts le cas échéant.
Dans sa version 4.0 (l'actuelle à la date où ce texte est écrit), de base, ce score se base sur 11 critères :
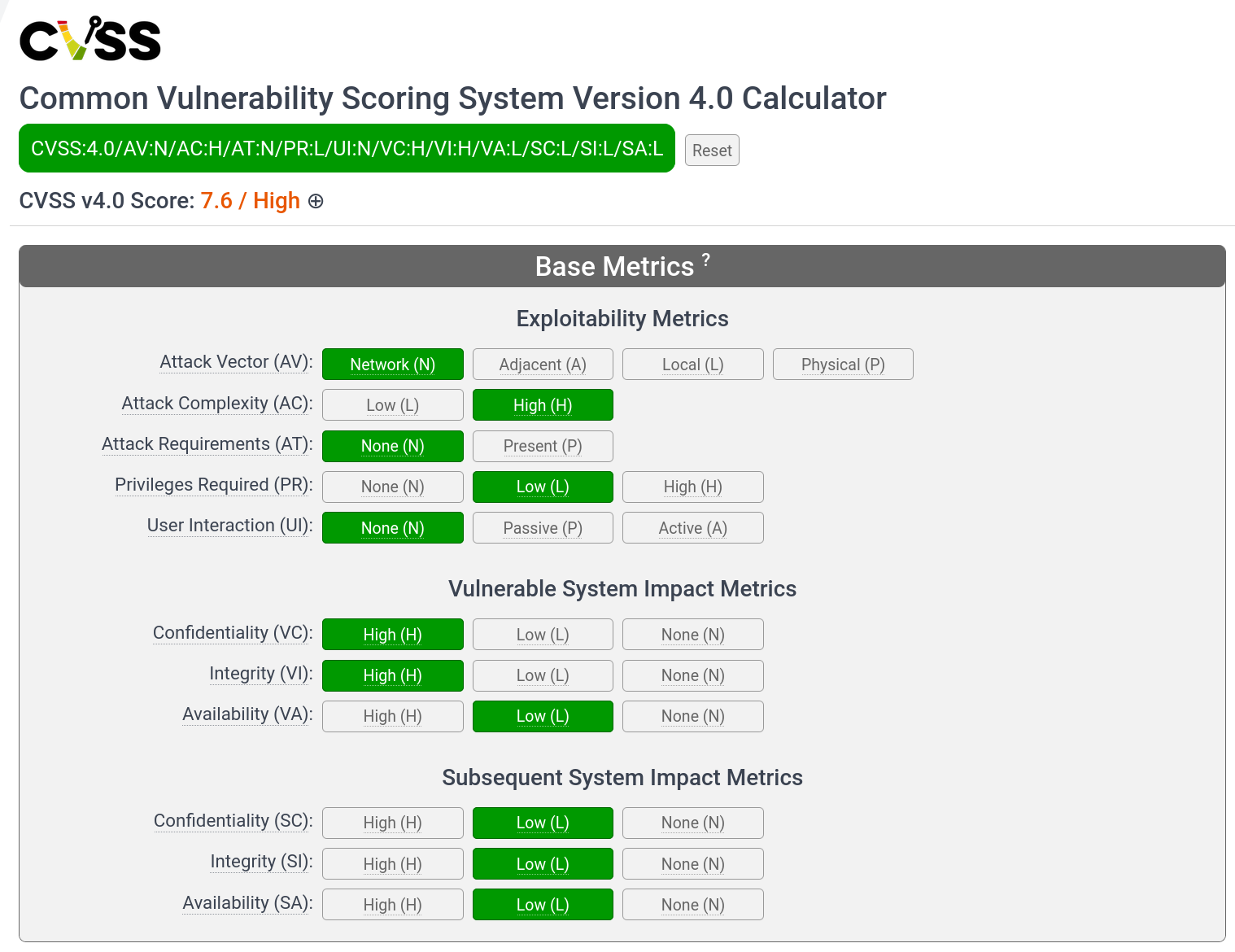
Dans l'exemple ci dessus est décrite une vulnérabilité ayant un score de 7.6, une sévérité dite "haute" (High).
Cette vulnérabilité est exploitable depuis Internet (AV:N), elle e complexe à exploiter (AC:H), il n'y pas de prérequis à l'exploitation (AT:N), il faut au moins être un utilisateur normal pour l'exploiter (PR:L), elle ne nécessite pas de piéger une victime pour être exploitée (UI:N).
Quand cette vulnérabilité est exploitée avec succès, elle dégrade fortement la confidentialité (VC:H) et l'intégrité (VI:H) de la cible, et faiblement sa disponibilité (VA:L). En cascade, l'exploitation réussie de la vulnérabilité menace, faiblement, la confidentialité (SC:L), l'intégrité (SI:L) et la disponibilité (SA:L) du système qui porte la cible.
Donc le score CVSS résume le risque de cette vulnérabilité en une seule note (ici 7.6). Mais il est aussi possible de restituer ses détails en fournissant ce qu'on appelle le vecteur CVSS (dans l'exemple CVSS:4.0/AV:N/AC:H/AT:N/PR:L/UI:N/VC:H/VI:H/VA:L/SC:L/SI:L/SA:L). Cela permet, en un minimum de place, de donner les éléments de contexte nécessaires à la prise de décision et à la priorisation.
Ça l'air super comme ça, mais le constat, assez partagé parmi les acteurs de terrain de la cybersécurité, c'est que le score CVSS est encore souvent défaillant à restituer correctement la criticité de certaines vulnérabilités. Donc c'est un outil utile mais encore imparfait.
0-day (zero-day)
Il s'agit d'une vulnérabilité qui touche un produit, mais dont l'éditeur ignore qu'elle existe.
Quand quelqu'un découvre une vulnérabilité, il peut :
- contacter d'abord l'éditeur du produit concerné pour lui laisser le temps de la corriger (en général 90 jours) en éditant une nouvelle version : on parle de "divulgation responsable" ou de "divulgation coordonnée" (responsible disclosure)
- rendre directement la vulnérabilité publique, l'éditeur doit alors la corriger le plus vite possible (il a 0 jours devant lui pour le faire, d'où le nom) : on parle alors de "divulgation complète" ou de "divulgation sauvage" (full disclosure)
- garder cette vulnérabilité privée (pour son propre usage)
- revendre cette vulnérabilité
On parle de 0 day dans les cas 2, 3 et 4 (même si pour le deuxième il y a une petite subtilité).
Si la vulnérabilité est gardée privée ou revendue (les cas 3 et 4), elle sera probablement utilisée contre le produit de l'éditeur. Par exemple si elle permet de se connecter en VPN, sans compte, sur un pare-feu Cisco, les pirates vont utiliser cette 0 day contre toutes les entreprises qui ont un pare-feu Cisco, avec fonction VPN, pour rentrer dans leur réseau.
« On s'est fait poutrer par une 0-day sur notre palo alto » = un pirate a infiltré notre réseau en utilisant une vulnérabilité inconnue sur notre pare-feu Palo Alto.
Quand une entreprise importante se fait pirater, généralement elle diligente une analyse forensic pour identifier comment le pirate est rentré, afin de combler la brèche. Donc après avoir utilisé cette 0 day une dizaine de fois, quelqu'un va finir par se rendre compte que le problème vient de ce pare-feu. Il va faire des recherches, identifier la vulnérabilité et prévenir Cisco pour que ces derniers sortent une mise à jour qui corrige le problème.
Dans le cas d'une divulgation sauvage, l'éditeur est pris dans une course. Maintenant que tout le monde sait que son produit est vulnérable, il doit publier un correctif et prévenir tous ses clients de l'installer le plus tôt possible AVANT que des pirates n'utilisent cette vulnérabilité contre eux. Le nom 0 day vient d'ailleurs de la blague que 0 c'est le nombre de jour dont dispose l'éditeur pour corriger (contre 90 dans le cadre d'une divulgation coordonnée).
Les 0-day posent un défi considérable en cybersécurité car elles constituent une menace pour laquelle il est impossible de se prémunir. Même en maintenant strictement à jour tous vos logiciels, vous pouvez quand même être victime d'une 0 day, puisqu'il n'existe pas encore de mise à jour qui la corrige.
Notamment, la plupart des groupes cybercriminels d'importance dispose d'un arsenal privé de 0-day.
Donc vous ne pouvez répondre à cette menace que par des mesures palliatives : segmenter le réseau, utiliser deux pare-feux de marques différentes, etc.
1-day ou n-day
Désigne une vulnérabilité qui a été rendue publique, pour laquelle l'éditeur a publié un correctif, mais qui n'a pas encore été installé par tous les clients.
« Ils sont rentrés avec une 1-day d'il y a 10 jour » = on a été compromis car un pirate a exploité une vulnérabilité dont l'éditeur avait publié le correctif il y a 10 jours, mais qu'on avait pas encore installé.
Correctif (patch)
Un correctif (patch en anglais) est une mise à jour qui vient corriger une vulnérabilité.
Ainsi, « patcher une vulnérabilité » ou encore « fixer une vulnérabilité » (de l'anglais to fix = corriger) signifie la corriger. Ce sont des termes fréquemment utilisés à l'oral.
Lorsque l'expression est employée en parlant de l'éditeur, cela veut dire qu'il a publié la mise à jour qui corrige. Lorsque c'est employé en parlant du client qui utilise le produit, cela veut dire qu'il a appliqué la mise à jour publiée par l'éditeur.
Car oui 90% des vulnérabilités se corrigent via l'application d'une mise à jour.
« Ce mois-ci Microsoft a patché 80 vulnérabilités critiques dans Windows» = Microsoft vient de sortir une mise à jour mensuelle qui corrige 80 vulnérabilités critiques qui affectent son produit Windows.
« Est-ce que vous avez pu patcher les Windows ? » = Avez-vous pu installer la mise à jour qui corrige les vulnérabilités de la version de Windows installée sur nos postes ?
Patch management
Le patch management c'est simplement la gestion de l'application des correctifs.
Vous allez me dire : "il y a vraiment besoin d'un mot pour ça ? Il y a des mises à jour, on les applique et c'est réglé. Gestion c'est peut être un peu grandiloquent pour décrire ça non ?".
Tendre naïveté. La gestion des mises à jour ...

C'est en fait un des sujets les plus critiques et les plus difficile à traiter.
En fait, une mise à jour publiée par un éditeur ne sert pas uniquement à corriger des vulnérabilités.
Le but premier est généralement de fournir de nouvelles fonctionnalités ou bien d'améliorer les fonctionnalités existantes. Le but secondaire est de corriger les bugs (et certains de ces bugs sont des vulnérabilités).
Le contenu d'une mise à jour est généralement décrit dans ce que l'on nomme un « changelog ».
Voici par exemple le changelog de la version 2.4.62 du logiciel Apache :

On peut y voir que deux vulnérabilités ont été corrigées (CVE-2024-40725 et CVE-2024-40898), 4 bugs ont été corrigés (là où il y a marqué Fix ... et Avoid ...) et 2 fonctionnalités mineures ont été ajoutées.
Le problème est qu'en installant une mise à jour pour corriger une vulnérabilité, vous installez aussi tout le reste qu'il y a dans la mise à jour, dont des modifications de fonctionnalités. Et si votre outil ne fonctionne plus exactement comme avant, cela peut entraîner des « régressions », aussi appelées des « ruptures fonctionnelles » (il ne délivre plus le service attendu comme souhaité). C'est notamment très fréquent lorsque cet outil s'interface avec d'autres et qu'il y a un changement dans le format de ce qu'il communique.
Par exemple, si votre outil inscrivait les dates au format 20/12/25 et que, dans la dernière mise à jour, l'éditeur a fait un changement pour que maintenant ce soit 20/12/2025 ... vous pourriez avoir un bug car l'outil qui utilise ces dates était configuré pour lire 8 caractères (donc si on lui donne 20/12/2025 il ne lira que 20/12/20 et pensera qu'il s'agit d'une date en 2020).
Donc, dans une entreprise, appliquer aveuglément les mises à jour des éditeurs c'est être à peu près sûr que plus rien ne marche comme prévu d'ici 1 ou 2 ans.
Alors comment fait-on ?
L'approche la plus commune est d'appliquer les mises à jour sur un échantillon du parc informatique seulement (20 machines par exemple), d'observer le comportement quelques jours/semaines, et si rien n'a l'air de bugger, on applique la mise à jour partout.
Dans les entreprises les plus grosses, on dédie même des machines uniquement au fait de tester que les mises à jour n'entraînent pas de bug. Ces machines sont appelées un « environnement de pré-production »(stagging en anglais). Et on n'attend pas passivement de voir s'il y a des bugs, on reteste activement toutes les fonctions pour s'assurer qu'elles marchent comme prévu (on nomme ceci des « tests de non-régression »).
Le problème que cela engendre est que si l'équipe informatique n'a pas assez de temps pour tester les mises à jour, elle préfèrera souvent de rien installer du tout, plutôt qu'installer aveuglément (c'est-à-dire sans certitude qu'il n'y aura pas de régressions).
D'où le nombre stratosphérique d'entreprises où 90% du parc n'est pas à jour et où il est donc assez facile pour un pirate de pénétrer car il y a plein vulnérabilités connues.
Rétroportage (backporting)
Le rétroportage consiste à prendre un correctif publié dans la version N+1 d'un programme et à l'appliquer à la version N. Le but est de pouvoir corriger la vulnérabilité sans avoir de rupture fonctionnelle.
Cette pratique est une des solutions aux problèmes du patch management.
C'est notamment ce qui est mis en oeuvre par deux versions très populaires de Linux que sont Debian et Ubuntu. Celles-ci sont connues pour assurer une très bonne stabilité et sont utilisées, pour cela, par des centaines de millions de serveurs (oui oui)... bien plus que Windows notamment.
Pour donner un exemple de comment ça se passe : mettons que le programme Apache en version 2.4.61 soit affecté par une vulnérabilité. Apache va sortir une version 2.4.62 qui corrige cette vulnérabilité ET qui ajoute d'autres trucs comme de nouvelles fonctionnalités (ce qu'on a décrit plus haut comme le problème de la rupture fonctionnelle). Ce que va faire Debian c'est prendre uniquement la correction de la vulnérabilité et l'appliquer à la version 2.4.61. Ainsi le programme Apache n'est plus vulnérable ET il continue de fonctionner comme avant.
Bon ils ne font pas ça infiniment non plus, tous les 4 ans, il faut passer à la nouvelle version et donc, là, affronter les possibles ruptures fonctionnelles. Mais tous les 4 ans c'est mieux que toutes les semaines.
Cette pratique a aussi le léger désavantage de créer des faux positifs de la part des scanners de vulnérabilités (qui vont dire "oula vous utilisez la version 2.4.61, elle a une vulnérabilité").
Algorithme
Un algorithme est une méthode pour atteindre un but, une succession d'étapes. C'est conceptuel,, ça peut aussi bien s'écrire dans un fichier que sur un coin de nappe. C'est différent d'un "programme" (un programme utilise des algorithmes)
Alors là on n'est plus vraiment sur une définition propre à la cybersécurité. C'est plutôt un terme d'informatique générale. Mais j'ai besoin de le définir pour que des termes comme reverse engineering soient explicables. Et puis ça ne fera de mal à personne car c'est vraiment l'exemple type du terme que le commun des mortels entend partout et ne comprend pas vraiment.
Par exemple, pour trouver la sortie d'un labyrinthe, il existe plusieurs algorithmes.
Le plus naïf est :
- Je vais tout droit
- Si je tombe sur un embranchement, je prends à gauche et je mémorise cet embranchement
- Si je tombe sur un cul de sac, je reviens au dernier embranchement mémorisé et je prends à droite au lieu d'à gauche et je supprime cet embranchement de ma mémoire
Une autre façon de faire est :
- Je vais tout droit
- Si je tombe sur un embranchement, je prends à ma gauche
- Si je tombe sur un cul de sac, je fais demi-tour
Les deux façons sont de méthodes valides pour trouver la sortie. Ce sont tous les deux des algorithmes. Mais là il n'y a encore rien d'informatisé (les algorithmes appartiennent à l'informatique théorique). Pourtant, même si l'on a encore rien programmé, c'est souvent là que se trouve la plus grosse valeur d'un programme (la plupart des secrets industriels des entreprises de la tech reposent sur des algorithmes qu'ils sont les seuls à avoir trouvés). C'est un domaine passionnant et très stimulant intellectuellement.
Implémenter
Quand on a un algorithme, on doit ensuite le transcrire en langage informatique. On appelle cela : « l'implémenter » ou encore « le coder ».
Cela consiste à faire passer le concept théorique à un fichier contenant des instructions informatiques (du « code »).
Donc le développeur choisit le langage informatique de son choix (les langages ont des spécialités : si on veut implémenter un algorithme pour un site Web, on utilisera le langage PHP, si c'est pour une application mobile, le Java, etc.).
Ça a à peu près cette tête :
def sortie_labyrinthe(joueur, carte):
while joueur.position != carte.sortie:
if joueur.position.type() == "coursive":
avancer(joueur)
if joueur.position.type() == "embranchement":
joueur.orientation = joueur.orientation - 90
avancer(joueur)
if joueur.position.type() == "cul-de-sac":
joueur.orientation = joueur.orientation - 180
avancer(joueur)
if joueur.position.type() == "sortie":
exit()Même sans tout saisir, vous devriez pouvoir deviner lequel de deux algorithmes a été implémenté ici.
Et là se trouve une mécompréhension partagée par pratiquement tous les moldus : ce langage informatique, ce n'est pas encore quelque chose de compréhensible par l'ordinateur. Vous allez me dire « mais c'est quoi l'intérêt si ce n'est ni compréhensible par les humains (car là on bite pas grand chose), ni par les ordis ?! ». En fait, c'est une façon d'écrire des instructions déterministes pour l'ordinateur ... tout en étant compréhensible par des humains ... avec un peu d'entraînement (si si).
Par "déterministe" on veut dire qu'il n'y a qu'un seul moyen d'interpréter ce qui est marqué. Ce qui n'est pas le cas du langage naturel des humains :

Il y a donc une étape supplémentaire pour transformer ce code informatique en 0 et 1.
Compiler
L'étape finale consistant à transcrire du langage informatique en 0 et 1 s'appelle «compiler». Ça se fait avec un compilateur (qui est un programme) à qui l'on donne notre code informatique (on dit aussi « code source »). À l'issue de la compilation, on obtient ce qu'on appelle un «binaire» (car il est fait de 0 et de 1).
Par exemple, un fichier .exe sur votre Windows, c'est un binaire.
Alors si vous essayez de l'ouvrir avec un éditeur de texte, vous n'allez pas voir les 0 et les 1. Ça va plutôt ressembler à ça :
\B9\6C\70\A5\0A\08\08\11\F0\E2\64\00\00\00\00\00\08\17\72\00\00\00\00\00\BA\57\00\00\00\00\00\00\A0\30\66\00\00\00\00\00\60\FC\65\00\00\00\00\00\40\00\00\00\00\00\00\00\00\00\00\00\00\00\00\00\00\00\00\00\00\00\00\00\00\00\00\00\00\00\00\00Car les ordinateurs lisent les 0 et 1 (les bits) par paquets de 8 qu'on appelle des octets (bytes en anglais), avec une représentation où 00000000 s'écrit \00 et 11111111 s'écrit \FF.
Et finalement votre processeur (le truc qui, à la toute fin de la toute fin, exécute les instructions) il a des règles pour dire "tel octet c'est quand je dois faire ci, tel octet c'est quand je dois faire ça".
On peut obtenir une vue de ce que comprend un processeur, lorsqu'il voit un binaire, avec un « désassembleur » qui est un programme remplaçant les octets par leur équivalent en instructions du processeur (ce qui se nomme le « langage assembleur »).
Pour notre programme de sortie d'un labyrinthe, ça donnerait quelque chose comme ça :
0000000000400000 <_start>:
400000: b9400021 ldr w1, [x1, #0]
400004: 7100003f cmp w1, #0x0
400008: 54000080 b.eq 0x400028 <coursive>
40000c: 7100043f cmp w1, #0x1
400010: 54000100 b.eq 0x400030 <embranchement>
400014: 7100083f cmp w1, #0x2
400018: 54000180 b.eq 0x400050 <culdesac>
40001c: 71000c3f cmp w1, #0x3
400020: 54000200 b.eq 0x400070 <sortie>
400024: 17fffff2 b 0x400000 <_start>
0000000000400028 <coursive>:
400028: 94000004 bl 0x400080 <avancer>
40002c: 17fffff0 b 0x400000 <_start>
0000000000400030 <embranchement>:
400030: b9400040 ldr w0, [x2, #0]
400034: 51000400 sub w0, w0, #0x1
400038: b9000040 str w0, [x2, #0]
40003c: 94000003 bl 0x400080 <avancer>
400040: 17ffffec b 0x400000 <_start>
0000000000400050 <culdesac>:
400050: b9400040 ldr w0, [x2, #0]
400054: 51000800 sub w0, w0, #0x2
400058: b9000040 str w0, [x2, #0]
40005c: 94000002 bl 0x400080 <avancer>
400060: 17ffffe8 b 0x400000 <_start>
0000000000400070 <sortie>:
400070: d2800000 mov x0, #0x0
400074: d2800ba8 mov x8, #0x5d
400078: d4000001 svc #0x0
0000000000400080 <avancer>:
400080: d65f03c0 retNormalement là votre premier réflexe c'est de dire "non mais notre algorithme il faisait trois lignes, notre code il en faisait 12 et là ton truc il en fait 32 !".
OUI ! À chaque étape on va plus loin dans le détail. Pour vous donner un ordre d'idée, faire une addition en langage informatique ça prend une ligne : a=1+2. En langage assembleur ça en prend 5 :
- Nommer une case a
- Mettre 1 dans une case W0
- Mettre 2 dans une autre case W1
- Mettre le résultat de la case W0 additionné à la case W1 dans la case W0
- Mettre le contenu de W0 dans la case a
Et ça ressemble à quelque chose comme ça :
ADRP X1, a
MOV W0, #1
MOV W1, #2
ADD W0, W0, W1
STR W0, [X1] Ce que j'ai vulgairement appelé les cases (qui s'appellent en réalité des registres) sont un peu comme des bols pendant que vous cuisinez : vous coupez des poivrons sur votre planche à découper puis vous les mettez dans un bol pour avoir cette planche disponible pour la découpe des oignons. Ça sert à stocker les résultats intermédiaires.
Votre second réflexe c'est de vous dire "la vache on comprend vraiment rien à ce qui est marqué là". C'est normal c'est fait pour être lu par le processeur, pas par un humain. Donc il n'y a pas de besoin que ce soit compréhensible.
Reverse engineering
C'est quand quelqu'un arrive à déterminer ce que fait un programme depuis le seul code assembleur.
Avant d'expliquer plus en avant le cœur du concept, il y a un élément fondamental à comprendre pour saisir le contexte : on sait passer d'un algorithme à un langage informatique puis à un langage assembleur, mais on ne sait pas faire l'inverse !
Cela parait contre intuitif car tout le processus de compilation (pour rappel : passer du langage informatique au langage assembleur) est accompli par un programme automatisé, dont le fonctionnement est connu. Pourquoi alors ce que ce compilateur fait dans un sens, ne pourrait-on pas le faire dans l'autre sens ?
En fait, nous, humains, avons besoin de "structurer", d'une certaine façon, ce que l'on écrit pour que ce soit compréhensible. Ce qui est écrit en langage informatique EST structuré d'une façon humainement compréhensible. Mais le processeur, lui, n'a pas du tout besoin de cette structure. Donc lors de l'étape de compilation, cette structure est "jetée", car elle serait inutile pour lui. C'est pour ça qu'on ne peut pas faire l'opération dans l'autre sens : on ne peut pas recréer ce qui a été détruit.
Pour faire une analogie : vous pouvez recadrer une photo. Les bords que vous avez supprimés sont alors perdus. Même si le processus qui a permis de recadrer la photo est parfaitement connu et n'a rien de sorcier, vous ne pouvez pas recréer les bords manquants depuis la photo recadrée.
Il existe des tentatives de reproduire du code informatique depuis le code assembleur. Mais c'est un peu comme demander à une IA de reconstituer les bords manquants d'une image : elle va devoir "imaginer" des bords qui sont "cohérents", mais qui ne seront pas forcément ceux d'origine.
Comme on vient de l'expliquer, le langage assembleur est imbitable pour un humain, même un programmeur.
Pourtant, une poignée d'élus masochistes ont réussi à le dompter et arrivent à comprendre ce que fait un binaire, sans l'aide du langage informatique. On appelle cela la rétro-ingénierie (reverse engineering), le reverse (prononcé "riveurse") pour les intimes. En quelque sorte ça consiste à redessiner les plans de fabrication depuis le produit fini.
C'est une des disciplines reines de la sécurité informatique car c'est très exigeant (il faut vraiment pratiquer en continu pour le pas perdre la main).
Mais alors à quoi ça sert ?
Premièrement ça aide à trouver des vulnérabilités. Il est bien plus simple d'identifier des points vulnérables dans un logiciel si vous êtes capable "d'ouvrir le capot" pour voir comment ça marche. L'alternative étant d'interagir avec ce programme "à l'aveugle" (on dit en blind ou en blackbox).
Deuxièmement ça aide à modifier des programmes. Par exemple, vous avez téléchargé Photoshop et au lancement il vous demande une clé de license. Si vous êtes doué en reverse, vous pouvez ouvrir le binaire, trouver l'endroit où il demande cette clé et simplement supprimer cette vérification. Ainsi vous pouvez utiliser le programme sans payer.
Troisièmement ça aide pour de l'espionnage industriel. Votre concurrent a développé un algorithme révolutionnaire qu'il garde jalousement. Vous pouvez télécharger son logiciel et tenter de comprendre le fonctionnement de l'algorithme d'après le binaire.Quatr
Quatrièmement ça aide pour l'analyse des maliciels (malware). Généralement les programmes malveillants sont sous la forme d'un binaire. Pouvoir faire du reverse sur ce binaire permet de comprendre les rouages de l'attaque : qu'est-ce qui est visé par le programme (les mots de passe, les fichiers, l'accès à la webcam, ...), avec qui et comment communique -t-il, comment fait-il pour éviter d'être détecté par l'antivirus, etc.
Obfuscation
Ce sont toutes les techniques que peut mettre en place un programme pour gêner sa rétro-ingénierie.
On a dit que le reverse engineering était particulièrement compliqué. Et bé en fait c’est encore pire que ça, car ceux qui craignent qu’on fasse du reverse sur leur binaire s’emploient à complexifier inutilement leur programme pour le rendre incompréhensible.
Donc vous pouvez passer 10 minutes à essayer de comprendre ce que fait une portion du langage assembleur, alors qu’en fait elle fait juste un truc trivial. Par exemple, voici un algorithme obfusqué qui en fait réalise seulement l’addition de a et de b :
a = 5
b = 6
c = 17
d = (189933838988003 / 37889609) / 9667699
e = a - c
f = b + d + e
g = a - d
resultat = f - e + gL’obfuscation peut prendre plusieurs formes : faire des tâches inutiles (du «code mort»), faire des tâches simples de manière compliquée, chiffrer des partie du code pour qu’on ne voit pas directement ce qui sera exécuté, etc.
Qui s’amuse à faire de l’obfuscation ? Principalement deux populations.
- Les éditeurs qui veulent éviter qu’on pirate leur programme (éviter qu’un concurrent leur pique leur savoir faire ou bien qu’un petit jeune utilise leur programme sans payer en faisant sauter la partie vérification de la licence).
- Les pirates qui veulent éviter que leurs maliciels (malwares) soient détectés par l’antivirus. Et là on peut entendre pirate dans le sens «groupe cybercriminel» ou «agence de renseignement étatique». C’est la même façon de procéder
Par contre, il y a une règle indépassable qui est à l’avantage de ceux qui font du reverse : on ne peut pas empêcher quelqu’un qui possède un binaire de l’analyser. Tout ce qu’on peut faire c’est rendre ça le plus difficile et pénible possible.
Par exemple, les équipes de développeurs de Photoshop expliquaient que leur but c’est que les reversers («riverseurs», ceux qui font du reverse) passent au moins un an avant d’arriver à casser le programme (c’est-à-dire à faire sauter la licence). Car, après un an, ils sortent une nouvelle version du programme, donc c’est moins de pertes financières si l’ancienne version est piratée.
Une règle qui par contre est à l’avantage des obfuscateurs, c’est qu’il est irréalisable (en tout cas actuellement) de faire du reverse engineering de manière entièrement automatisée.
Donc les antivirus ne peuvent pas arrêter 100% des programmes malveillants qui sont obfusqués.
Débugger
(Prononcé «débeugué») C'est une façon de regarder ce qu’il se passe dans un programme pour identifier pourquoi il fonctionne mal.
Un logiciel «en production» (c’est-à-dire dans l’état où il est utilisé par les clients) est généralement une boite noire : on lui donne des données, il fait des traitements dessus et nous donne des résultats.
Mais l’utilisateur n’a pas accès à ce qu’il se passe sous le capot (les fameux traitements).
Si quelque chose fonctionne mal, il ne peut donc pas savoir exactement pourquoi et le corriger lui-même (sauf à faire du reverse engineering), il peut seulement en avertir l’éditeur.
Cet éditeur dispose généralement d’une version de «débug» de son logiciel. C’est une version qui marche comme le programme commercialisé, à la différence qu’il communique toutes les étapes intermédiaires de ses traitements internes. C’est donc une version «capot ouvert» du logiciel. Cela permet de localiser plus rapidement l'étape qui ne s'est pas déroulée comme prévu.
Un éditeur n’a pas intérêt à commercialiser une version de son programme permettant le debug, car ceci faciliterait grandement la copie de son logiciel par ses concurrents.
Dark Net
C'est à la fois une façon anonyme de se connecter à Internet et aussi un ensemble de sites Web accessibles seulement de cette manière.
Deep Web, Dark Web, Dark Net. Il fût un temps où ces termes fleurissait à tout va dans les articles de presse.
Remettons un peu tout ça au propre.
Le «Deep Web», c’est un truc à part qu’on va évacuer tout de suite. C’est le «Web non indexé», tout ce que ne voient pas les moteurs de recherche.
Je me rappelle d’articles putaclics qui tonitruaient que «on estime que le deep Web est 10 fois plus grand que le Web indexé».
Ouuuuua c’est comme un nouveau continent alors ?
En fait non. Si ce n’est pas indexé, très souvent, c’est que ce n’est pas accessible ... donc on s’en fout que ce soit 10 ou 1000 fois plus grand.
Par exemple, quand vous allez sur le site de votre banque en ligne : il y a la page d’accueil, puis la page de connexion, puis la page de votre profil, puis la page pour le détail des opérations de votre compte, la page pour les virements, la page pour contacter votre conseiller, la page pour le RIB, etc. En fait, bien qu’il y ait des dizaines de page, il n’y en a que deux qui sont publiquement accessibles : les deux premières. Tout le reste, il faut être connecté avec un compte client. Donc c’est inaccessible pour les moteurs de recherche. C’est ça le deep web.
Donc c’est un peu le même niveau d’utilité que si je vous disais qu’à 50 milliards d’années lumières il y a plein de ressources minières... c’est vrai ... mais ça vous fait une belle jambe.
Mais il arrive que des gens emploient le terme deep web pour en fait parler du web «underground». C’est presque toujours une erreur de l’utiliser de cette manière.
Maintenant : le Dark Net. C’est le concept général d’accéder à un réseau de manière anonyme.
Quand vous naviguez sur Internet, vous dialoguez avec le reste du réseau à l’aide d’une adresse IP. La ressource à laquelle vous allez vous connecter (TikTok, YouTube, Google, ChatGPT, ...) connait votre adresse IP (elle en a besoin pour vous répondre).
Et bien un Dark Net ça se matérialise en général par un protocole permettant de vous connecter sans révéler votre adresse IP. C’est une sorte de surcouche d’Internet.
Aujourd’hui on parle partout des VPNs. Ce ne sont pas des Dark Net. Dans un Dark Net, personne ne peut faire le lien entre vous et la ressource que vous consultez. Or avec un VPN, le fournisseur du VPN lui le peut. Ce n’est pas de l’anonymat.
Quand on parle de Dark Net, c’est souvent qu’on parle du réseau Tor. Tor est un protocole d’anonymisation. Mais Tor n’est pas «le» Dark Net, c’est «un» Dark Net. Il en existe d’autres, notamment des plus anciens (FreeNet).
Le fonctionnement de Tor, c’est que vous allez rebondir par plein de machines sur Internet, avant d’arriver à votre destination finale, de sorte qu’aucune d’entre elles ne sait qui vous êtes et où vous allez.
Enfin le Dark Web. Souvent le terme est utilisé comme synonyme de Dark Net. Mais on peut y mettre une petite nuance.
Tor, en plus de fournir de l’anonymat pour la navigation Internet, permet aussi de publier un site Web de manière anonyme. Pour cela Tor a créé une nouvelle extension de domaine : le .onion (au lieu de .fr, .com, etc). En publiant votre site en .onion, seuls les utilisateurs de Tor peuvent s’y connecter et personne ne peut localiser ce site.
Cet ensemble de sites anonymes c’est le Dark Web. C’est donc une sous-partie du Dark Net, au même titre que le Web normal est une sous-partie d’Internet.
Maintenant à quoi ça sert ?
L’anonymat fourni par les Dark Nets est essentiellement utilisé par 3 populations :
- le monde du crime : pour acheter et vendre des trucs (armes, drogues, humains, vulnérabilités, films piratés, ...) sans se faire attraper
- les dissidents : dans les états qui contrôlent fortement Internet, c’est une façon pour les opposants politiques de se réunir, de se coordonner, de discuter entre eux et avec l’extérieur, d’accéder à des informations censurées chez eux, etc.
- les gens soucieux de leur intimité : ceux qui considèrent que l’anonymat devrait être la façon normale de se connecter à Internet, car ils ne veulent pas être traqués par les états et les régies publicitaires
Enfin pour dire un mot rapide sur les débats qu’il peut exister : faut-il interdire les Dark Net car le crime y prospère comme jamais ?
L’avis des experts en cybersécurité est plutôt que non. Car si on l’interdisait (si tant est qu’on le puisse techniquement), les criminels trouveraient un autre espace sans difficulté insurmontable. Par contre les dissidents politiques, eux, ils n’auraient pas facilement d’alternative.
Une précision importante est qu’on n’a encore jamais trouvé de moyen d’être 100% anonyme sur Internet. Même avec Tor, il existe toujours des conditions particulières où l’on pourrait vous identifier.
Compromettre
C'est le mot poli pour dire « pirater ». Compromette une cible (un poste utilisateur, un serveur, un site Web) veut dire "en devenir administrateur" = "avoir les pleins pouvoirs sur cette cible".
Il y a des vulnérabilités qui, lorsqu'elles sont exploitées contre une cible, permettent de la compromettre.
Mais certaines vulnérabilités, moins graves, "dégradent" seulement la sécurité de la cible (par exemple en révélant certaines de ses données) sans pour autant compromettre entièrement cette cible.
Pown / Pwn
Se prononce "pone". C'est le mot d'argot pour dire «pirater».
Pour la machine qu'on a pwn, on dira qu'elle s'est faite pwn ou bien qu'elle est pwnd/powned (poned).
« J'ai pwn le serveur SAP » = j'ai piraté le serveur SAP.
« Je me suis fait pwn le serveur SAP » = quelqu'un a piraté mon serveur SAP
« Le serveur SAP est pwned » = le serveur SAP a été piraté
Exploit / PoC
Le plus souvent prononcé à l'anglaise (ex-ploï-te).
C'est un programme informatique automatisant l’exploitation d’une vulnérabilité, de sorte que même une personne avec des compétences limitées puisse compromettre une cible vulnérable.
Une vulnérabilité informatique peut être connue de tous (on dit qu'elle est publique) mais sa description peut demeurer vague.
Par exemple :
«An issue has been discovered in GitLab CE/EE affecting all versions starting from 13.1 prior to 16.10.7, starting from 16.11 prior to 16.11.4, and starting from 17.0 prior to 17.0.2. It was possible for an attacker to cause a denial of service using maliciously crafted file.»
On sait qu'il est possible de créer un déni de service via un fichier spécialement conçu dans ce but. Mais on ne sait pas comment on doit le concevoir exactement, où on doit l'envoyer, etc.
Pour avoir plus de détail, il faut généralement chercher un article produit par le découvreur de la vulnérabilité (la plupart du temps un chercheur en cybersécurité) où il explique sa démarche et fournit un PoC (Proof of Concept).
Un PoC est une « preuve de concept », c'est-à-dire un démonstrateur qui permet de prouver que la vulnérabilité, que le découvreur prétend avoir trouvée, existe bien. Dans les faits, c'est généralement un petit programme informatique qui automatise l'exploitation de la vulnérabilité en permettant d'accomplir quelque chose qui serait impossible si la vulnérabilité n'existait pas.
Par exemple, un PoC peut démontrer qu'il y une vulnérabilité dans les panneaux de comptabilisation des places de parking en remplaçant le nombre de places par autre chose :

Mais il arrive que les découvreurs de vulnérabilité ne rendent pas leur PoC public. ils l'envoient à l'éditeur pour lui prouver qu'il y a une faille dans son produit, mais ne le publient pas sur Internet pour éviter que des cybercriminels ne l'utilisent.
Il arrive aussi que certaines vulnérabilités soient découvertes par l'éditeur lui-même (par exemple au cours d'une revue de code). Il n'a alors aucun intérêt à donner des détails précis sur la façon d'exploiter cette vulnérabilité.
Dans ce cas, il faut comparer les différences entre la version qui corrige le problème (dans notre exemple 17.0.2) et la version juste avant qui était encore vulnérable (17.0.1). En regardant ce que l'éditeur a changé, on peut inférer où se trouvait plus précisément le point vulnérable et comment il marchait.
Donc en fait, un serveur peut tout à fait être touché par une vulnérabilité connue de tous ... mais personne ne sait l'exploiter (à part son découvreur).
Jusqu'au moment où quelqu'un se sera penché sur les détails, aura compris comment marche la vulnérabilité et aura écrit un petit programme qui permet d'automatiser l'exploitation (pour ne pas avoir à refaire les étapes manuellement à chaque fois) : il a alors écrit un exploit !
La différence entre un exploit et un PoC c'est la source et la finalité. Trivialement : on dit «PoC» quand le programme est écrit par un gentil, qui veut seulement démontrer que la vulnérabilité existe (son programme ne fait rien d'irréversible). On dit «exploit» quand c'est écrit par un méchant et que le programme sert à compromettre la cible vulnérable.
Quand quelqu'un a réussi à écrire un exploit/PoC, il peut alors se passer trois choses :
- soit il le rend public (ce que font généralement les chercheurs en cybersécurité)
- soit il le revend (il y a des plateformes pour vendre et acheter des exploits, ça peut valoir entre 1 000 et 1 000 000 €)
- soit il le garde privé pour être le seul à pouvoir l'utiliser (ce que font les agences de renseignements et les groupes cybercriminels)
Mais globalement, une fois qu'un exploit existe pour une vulnérabilité, ça change grandement la donne. Désormais, tous ceux qui sont affectés par cette vulnérabilité peuvent être attaqués par ... n'importe qui sachant lancer un programme (ça fait du monde).
« J'ai lancé un exploit sur tous leurs FTP, j'ai pwn 5 serveurs » = J'ai exécuté un programme permettant d'exploiter une vulnérabilité affectant certaines versions du programme FTP et il y a 5 serveurs où ça a marché (donc qui devaient être dans une des versions vulnérables) et dont je suis devenu administrateur.
Par abus de langage, on dit que quelqu'un "achète une vulnérabilité" ou "achète une 0 day" sur le Dark Net. Alors qu'en fait c'est surtout l'exploit qu'il paye. À la limite, il n'a même pas du tout besoin de comprendre la vulnérabilité.
En tant qu'acteur offensif (agence de renseignement, groupe cybercriminel, ...), la collection d'exploits dont vous disposez constitue votre arsenal. C'est EXTRÊMEMENT précieux.
En 2017, un groupe de hackers a réussi à voler l'arsenal de la NSA, qui contenait des dizaines d'exploits. L'un de ces exploits exploitait une 0 day de Windows, permettant d'en prendre le contrôle total à distance. Cet exploit a été utilisé quelques mois plus tard pour créer la plus grosse cyberattaque de l'Histoire : WannaCry.
Bug Bounty
C'est l'activité consistant, pour un éditeur, à rémunérer les personnes qui lui remontent des vulnérabilités de son produit.
Pour aborder le sujet comme il convient, il faut expliquer quelque chose que l'on a gardé flou jusqu'ici : qui trouve des vulnérabilités et dans quel contexte.
Qui découvre les vulnérabilités dans les programmes ?
- L'éditeur du programme lui-même. En effet, les développeurs d'un programme ont de multiples occasions de détecter qu'il y a une vulnérabilité dans leur produit. Ce peut être au cours de tests, ou bien d'une revue de code (un développeur va contrôler ce qui a été développé par un de ses collègues pour s'assurer qu'il n'y a pas d'erreurs (une pratique très saine mais trop rare)), ou encore via des outils dédiés à la détection de vulnérabilités, etc.
- Les utilisateurs de ce programme. Au cours de leur utilisation ils vont rencontrer des cas de figure non prévus par les développeurs (des bugs), dont certains peuvent constituer des vulnérabilités.
- Des chercheurs (publics ou privés) en cybersécurité. Ils se disent que tel programme est quand même utilisé par plein de monde et que ce serait intéressant de voir s'il n'y aurait pas des vulnérabilités dedans.
- Des cybercriminels. Ils se disent exactement la même chose que les chercheurs sauf que leur but derrière c'est de tirer profit des vulnérabilités trouvées.
- Les pentesters. Bien que la majorité de leur travail consiste à détecter si une entreprise est touchée par des vulnérabilités «connues», il n’est pas si rare qu’au cours d’un test d’intrusion, ils en découvrent qui ne sont pas encore répertoriées.
- Enfin : les technophiles curieux (les ados à capuche). Ceux qui simplement s’amusent à inspecter le fonctionnement des programmes pour comprendre comment ils fonctionnent
Historiquement c’était énormément la 6ème catégorie (les hackers) qui faisait le travail et très peu la première.
Or, que se passait-il lorsque quelqu’un découvrait une vulnérabilité (disons dans les cas 2, 3, 5 et 6 de la liste ci-dessus) ?
Généralement le découvreur notifiait l’éditeur du programme vulnérable, qui corrigeait la vulnérabilité (... des fois). Et donc le découvreur était gratifié d’un «merci» de la part de l’éditeur (... ou bien de menaces), de la gloire et de la reconnaissance de ses pairs.
Sauf que quand le marché de la vulnérabilité s’est développé, les «merci» et la gloire ça faisait un peu léger par rapport à la possibilité de gagner plusieurs milliers d’euros.
Car oui, des acteurs ont émergé pour acheter des failles informatiques afin de les utiliser à leur profit ou des les revendre.
Au début c’était uniquement des acteurs cybercriminels (donc ça aurait était un peu borderline pour les cas 3 et 5 de leur vendre). Mais déjà c’était intéressant car en vendant la vulnérabilité qu’on avait découverte, on pouvait être payé sans avoir à l’exploiter soi-même contre des entreprises. Donc on pouvait être rémunéré sans rien faire d’illégal ... si ce n’est avoir fourni une arme informatique à des malfaiteurs.
Mais ensuite, des plateformes légales sont apparues (on suppose qu’ils revendent les vulnérabilités essentiellement aux agences de renseignement des différents états). Et donc là ça devenait bien plus rentable (et sans risque juridique) de leur vendre les vulnérabilités, plutôt que d’en notifier l’éditeur.
C’était même moins risqué, car il arrivait que des éditeurs portent plainte contre ceux qui leur avait remonté des vulnérabilités (au motif que leurs CGV interdisaient d’aller trifouiller dans leur programme).
Et vous ne pouvez pas faire les deux. La vulnérabilité a de la valeur tant qu’elle demeure ignorée de l’éditeur (tant que c’est une 0 day). Après ça on dit qu’elle est «cramée». On ne pourra plus l’exploiter que contre les utilisateurs qui n’ont pas mis à jour le programme (alors qu’avant ça on peut l’exploiter contre tous les utilisateurs sans qu’ils n’aient de moyen de se protéger).
Et si vous êtes doué, vous pouvez assez vite vous payer des vacances aux Seychelles. Les prix peuvent ressembler à ceci (2,5 millions de dollars pour une vulnérabilité permettant de compromettre automatiquement un smartphone) :

Donc les éditeurs ont commencé à découvrir leurs vulnérabilités non plus via un gentil email d’un hacker au coeur pur, mais via les titres de presse indiquant que des cybercriminels utilisaient leur programme pour pénétrer dans les réseaux des entreprises.
Le genre de publicité dont on se passerait.
Ce qui a été un environnement propice à l’émergence des programmes de Bug Bounty. Ça se matérialise sous la forme de sites Internet où des entreprises et des hackers s’inscrivent. Les entreprises autorisent les hackers à chercher des failles sur leurs produits et les rémunèrent quand ils en trouvent. Généralement le mode opératoire c’est que l’éditeur reçoit la vulnérabilité en privé, il paye le hacker, il dispose d’un certain temps pour corriger, puis le hacker peut rendre la vulnérabilité publique.
Il existe plusieurs sites de Bug Bounty. On y est généralement moins bien payé qu’en les revendant au marché noir, mais c’est plus chevaleresque, donc ça trouve son public.
Weaponization
Il s'agit du fait d'acquérir (développer ou acheter) des moyens d'exploiter les vulnérabilités d'une cible.
Par exemple, si vous avez détecté que votre cible est affectée par une vulnérabilité sur son site Web, mais qu'il n'existe pas d'exploit public pour l'utiliser, vous pouvez en développer un.
Si vous n'avez pas trouvé de vulnérabilité connue contre votre cible, vous pouvez tenter d'acheter une 0 day, sur le Dark Net, qui affecte un outil utilisé par votre cible (par exemple son pare-feu ou Microsoft Word).
Script Kiddies
Dans le milieu de la cybersécurité, on distingue généralement les script kiddies (des gens faiblement compétents qui utilisent seulement des exploits écrits par d'autres) des experts (qui eux écrivent les exploits).
Force brute
L’attaque par force brute (bruteforce en anglais) consiste à essayer exhaustivement toutes les possibilités contre un secret (par exemple un mot de passe) jusqu’à trouver la bonne.
Un pirate voulant trouver votre mot de passe sur un site Web peut trivialement essayer séquentiellement toutes les possibilités : «a», «b», «c», ... «A», «B», ... «0», «1», ... «aa», «ab», «ac», ... «aA», «aB», ... «a0», «a1», ...etc.
En deux mots c’est ça la force brute. On dit aussi qu’il essaye de «bruteforcer» votre mot de passe.
Le jargon plus professionnel peut parfois employer les termes «d’attaque exhaustive» ou «d’attaque itérative».
Mais ça va être super long me direz-vous ?
En fait, il ne teste pas ces mots de passe lui-même (où il aurait du mal à réaliser plus d’un essai par seconde). Il va utiliser un programme pour automatiser ça. Et donc là, le fait que ce soit long ou pas va dépendre de la vitesse à laquelle il peut tester et de la complexité de votre mot de passe.
Certaines attaques peuvent atteindre les 10 milliards d’essais par seconde. Donc si votre mot de passe c’est le nom de votre fille : «Laura!», le pirate mettra 19 heures pour tester toutes les combinaisons de minuscules, majuscules, chiffres et ponctuation avant de tomber sur la bonne.
Initialement j’ai donné l’exemple d’un bruteforce contre le mot de passe de votre compte sur un site Web (Instagram, Tiktok, LinkedIn, ...). Mais c’est généralisable à tout ce qui est un secret : un mot de passe donc, mais aussi une clé de chiffrement, un code PIN ou encore le nom d’une ville (si par exemple votre question de sécurité est «la ville de naissance de votre mère»).
Seulement, une attaque par force brute a forcément besoin d’un truc pour marcher : un «oracle». C’est-à-dire quelque chose qui lui indique si la possibilité testée est la bonne ou pas.
Quand un pirate essaye de bruteforcer un compte sur un site Web, c’est ce site Web qui va agir comme un oracle : il lui indiquera «mot de passe incorrect» chaque fois que le candidat testé sera mauvais et «bienvenue» quand il aura trouvé le bon.
Si je veux brutefocer la combinaison d’un cadenas, ce cadenas agit comme oracle car il m’indique qu’un essai est mauvais en ne s’ouvrant pas.
Cela peut sembler trivial dit comme ça, mais il existe en fait plein de configurations où les pirates ne disposent d’aucun oracle pour réaliser une attaque par force brute.
Par exemple, si un pirate veut bruteforcer votre code PIN, mais qu’il n’a pas votre téléphone sous la main, alors il n’a pas d’oracle. Il peut alors bien itérer toutes les combinaisons possibles s’il veut, il n’a nulle part où les tester pour distinguer la bonne.
Réussir une attaque par force brute nécessite un niveau d’interaction minimal avec la cible.
Ce type d’attaque existe depuis très longtemps et de plusieurs protections ont été mises en place au fil du temps pour s’en prémunir.
La plus connue est de limiter le nombre d’essais. Si au bout de 3 mots de passe essayés, le site Web vous répond «compte bloqué», même si vous pouvez tester des milliards d’essais par seconde, vous n’êtes pas plus avancé.
Il existe d’autres types d’attaque contre les mots de passe.
L’alternative la plus fréquente est l’attaque par dictionnaire (wordlist). Le pirate va itérer les candidats d’une liste de mots plutôt que de tester séquentiellement toutes les possibilités. Par exemple, pour une attaque contre un mot de passe, il pourra utiliser la liste des 1 millions de mots de passe les plus couramment utilisés.
L’autre alternative est l’attaque par mot probable. Le pirate glane toutes les informations qu’il peut sur vous et s’en sert pour construire une liste de mots de passe probables : le nom de votre chien, de vos enfants, votre date de naissance, le lieu où vous avez grandi, etc. Il peut aussi les combiner et les dériver (toulouse, TOULOUSE, Toulouse, T0ul0use, Toulouse!, tou1ou$3, ...).
Blackbox
Open source
Porte dérobée (backdoor)
C'est une façon de s’octroyer un accès «clandestin» à un système.
«Clandestin» dans le sens où c’est généralement accompli à l’insu du propriétaire dudit système.
«Système» est ici entendu au sens large : un ordinateur, un smartphone, un site Web, ...
Le plus généralement, ce terme désigne les modifications/ajouts effectués par un pirate, après avoir réussi une intrusion initiale, pour pérenniser son accès sur la cible.
Souvent, c’est même la première chose qu’il cherche à faire, avant de commettre une malversation quelconque.
En effet, il y a de nombreux cas de compromission où le temps dont dispose le pirate, pour mener ses actions, est très court.
Par exemple, dans le cas du phishing avec un fichier docx piégé. L’accès que le pirate obtient, sur l’ordinateur de sa cible, ne dure que le temps où ce fichier est ouvert. Or, généralement, la victime ne l’ouvre que quelques secondes/minutes. Trop peu de temps pour explorer le réseau, trouver tous les fichiers, les exfiltrer, les chiffrer, déposer une demande de rançon, etc.
Même dans le cas, plus stable, de l’exploitation d’une vulnérabilité contre un serveur, le pirate pourrait perdre son accès à tout moment si l’administrateur met à jour le composant vulnérable.
Pour toutes ces raisons, le pirate va chercher, avant tout, à «sécuriser» son accès frauduleux, afin de pouvoir réentrer à volonté sur la cible, lorsque la connexion est perdue.
Cela peut se matérialiser de plusieurs façons.
La porte dérobée peut trivialement être un programme que le pirate installe sur le système. Ce programme est configuré pour se lancer tout seul au démarrage et établir une connexion vers le pirate.
Mais ça peut aussi être bien plus simple : par exemple, le pirate crée un utilisateur sur le système. Comme ça, chaque fois qu’il veut se connecter à cet ordinateur, il n’a plus besoin de le pirater (via un exploit) mais seulement de s’y connecter, avec son utilisateur (comme le ferait tout visiteur légitime).
Dans tous les cas, l’idée générale est de disposer d’un moyen de garder le contrôle du système même lorsque la victime a comblé la vulnérabilité qui avait initialement permis de pénétrer sur ce système.
Mais le terme backdoor désigne aussi autre chose : le fait d’incorporer un accès secret dans un composant, lors de sa conception, pour pouvoir y accéder à l’insu de ses utilisateurs. On parle aussi de «mouchard».
Quand on parle de «composant», ce peut être un dispositif électronique, un logiciel, etc.
Ça peut être réalisé par un constructeur pour espionner ses clients.
Ça peut être réalisé par un état, à l’insu du constructeur (par exemple en s’introduisant de manière clandestine dans l’usine de fabrication) ou en coordination avec lui.
Ce peut être fait aussi sur un petit échantillon de ce composant (1 sur 10 000 par exemple) pour ne pas être détecté par les tests de produit.
Les cas de backdoor de la part des constructeurs sont toujours un peu difficiles à juger car il y a un déni plausible : dire que c’était une interface de debug qu’ils ont oublié de supprimer pour la mise en production ou que c’était une vulnérabilité qu’ils n’avaient pas vue.
Enfin, on parle aussi de backdoor pour désigner un moyen alternatif de déchiffrer des données.
Quand un algorithme de chiffrement est utilisé pour sécuriser des données, le principe est que seuls l’expéditeur et le destinataire (qui possèdent la clé) peuvent accéder au contenu.
Quand vous vous connectez en HTTPS à un site Web, votre navigateur et ce site conviennent d’une clé secrète pour pouvoir communiquer (ça se fait en quelques millisecondes, «sous le capot»).
On dit qu’un système de chiffrement (un cryptosystème) est «sûr» lorsqu’il n’existe pas de moyen, réalisable en un temps raisonnable, d’accéder aux données chiffrées, sans posséder la clé secrète.
Par exemple, pour accéder aux données chiffrée en RSA 2048 bits (un système de chiffrement actuel réputé sûr), sans disposer de la clé secrète, il faut «bruteforcer» cette clé. En l’état actuel ça prendrait plusieurs fois l’âge de l’Univers pour y arriver.
SAUF ...
Sauf si celui qui a créé le cryptosystème y a caché un moyen alternatif de contourner (de «bypasser» pour employer le barbarisme commun) la nécessité de bruterforcer.
Par exemple, des experts se méfient de certains cryptosystèmes, sélectionnés par les Etats-Unis, dont des paramètres semblent bizarrement choisis. Ceci peut laisser penser que la NSA y a introduit des backdoor.
Je dis «laisser penser» car il n’est pas aisé d’être certain de l’absence d’une porte dérobée dans un cryptosystème.
En effet, pour introduire une backdoor dans un système de chiffrement, il y a plusieurs façons.
Si ce système est une «boite noire», alors le créateur peut simplement mettre en place un double chiffrement : un premier avec la clé de l’utilisateur, un second avec sa clé. Ainsi il pourra toujours tout déchiffrer, même sans posséder la clé de l’utilisateur.
Quand le système est open source (le plus répandu pour la cryptographie), vous ne pouvez pas faire quelque chose d’aussi voyant. Les systèmes cryptographiques reposent sur des fonctions mathématiques assez alambiquées. Introduire une backdoor dans ces systèmes repose en général sur le fait d’avoir connaissance d’une manière alternative (et plus simple) d’effectuer une des opérations. Pour les utilisateurs, avoir la certitude qu’il n’y a pas de backdoor nécessite d’avoir la preuve (au sens mathématique) qu’une telle manière alternative n’existe pas. Mais obtenir «la preuve de l’absence de quelque chose» c’est toujours super difficile.
Donc l’état de l’art c’est de plutôt faire confiance aux cryptosystèmes conçus par des experts non affiliés, plutôt qu’à ceux sponsorisés par des États.
La plupart des propositions législatives concernant l’introduction de moyens de déchiffrement des communications grand public (aux fins de lutte contre la criminalité) reposent généralement sur l’introduction d’une backdoor, par le fournisseur, dans son algorithme de chiffrement.
Malware / virus
Maliciel en français. C’est un programme informatique malveillant.
Tout d’abord, il existe tout un «bestiaire» des maliciels où l’on distingue précisément un ver (worm), d’un virus, d’un cheval de Troie (trojan), etc.
Franchement ... on s’en fiche un peu.
Vous aurez toujours un puriste pour vous dire «non ce n’est pas un virus, c’est un ver». Mais le paysage actuel de la menace fait que les programmes malveillants que l’on dépose sur votre ordinateur sont pratiquement toujours protéiformes. Ils sont à la fois des chevaux de troie, des rootkit, des virus, ...
Donc en utilisant le terme générique «maliciel» (malware en anglais, contraction de malicious software), vous parlez de cette catégorie en entier et ce niveau de précision sera pratiquement toujours pertinent. En utilisant le terme «virus», vous le serez moins, mais on comprendra quand même de quoi vous voulez parler.
Bien maintenant : que fait un maliciel ?
Ça peut être tout un tas de malversations (en général c’est plusieurs à la fois), les plus communes sont :
- permettre à un pirate de prendre le contrôle de votre machine à distance
- espionner votre activité (navigation internet, webcam, micro, ...)
- voler vos informations importantes : mots de passe, numéros de CB, clé WiFi enregistrées, accès VPN de l’entreprise, etc.
- chiffrer vos données pour ensuite vous demander une rançon
- exfiltrer vos données pour ensuite les revendre ou vous demander une rançon contre le fait de ne pas les divulguer
- installer une porte dérobée sur votre ordinateur, permettant de récupérer un accès si vous arriviez à supprimer le maliciel
- essayer de se répliquer sur d’autres ordinateurs du réseau où vous êtes connecté
- détruire les données et le système d’exploitation pour que votre ordinateur devienne inopérant
- etc.
Peut être allez vous demander : «c’est pas un peu comme un exploit ?».
Pas exactement.
L’exploit permet d’exploiter une vulnérabilité pour ... faire ce qu’on veut ensuite. Le maliciel ça va plutôt être la partie «faire ce qu’on veut ensuite». Donc, plus précisément, ce qu’il se passe c’est qu’un pirate va utiliser un exploit pour installer un maliciel sur le système vulnérable. L’exploit agit un peu comme la clé permettant de rentrer par effraction. Et le maliciel c’est l’intrus (il peut casser des trucs, voler des trucs, mettre des micros, etc.).
MAIS !
Nous avons dit qu’un maliciel pouvait chercher à se répliquer sur d’autres machines du réseau. Souvent, pour ce faire, il va devoir embarquer des exploits permettant d’exploiter les éventuelles vulnérabilités de ces autres machines du réseau.
Donc pour être plus complet, on devrait dire que l’exploit sert à installer le maliciel sur la cible, maliciel qui peut comporter lui-même des exploits.
Je vous invite à aller lire la partie «Kill chain» pour plus de détail sur le déroulement typique d’une attaque.
Privacy
C'est un terme qu’on traduit trop souvent par «vie privée» mais qui signifie plutôt «intimité».
Ce concept est malheureusement intraduisible directement en français. Aucun de nos mots ne recouvre précisément toutes ses nuances (un mélange de vie privée, d’intimité, d’anonymat, d’inviolabilité, ...).
Cela produit souvent une distorsion dans les débats à propos de la confidentialité sur Internet.
La privacy est une notion qui va intervenir essentiellement sur les sujets suivants :
- les ressources que vous consultez sur Internet
- les messages que vous envoyez/recevez via Internet
- les lieux (physiques) que vous visitez
- les dispositifs de captation dont vous disposez (webcam, micro, caméra, ...)
- les informations à propos de vous (sexe, age, taille, emploi, intérêts, opinions, ...)
Pour chacun de ces sujets, les questions qui se posent sont :
- quelqu’un va-t-il collecter ces informations ?
- qui va y avoir accès ?
- dans quel but ?
Trop souvent, on imagine que ces données ne sont «sensibles» que si elles concernent la sexualité : vous consultez le site extreme-hardcore-zoophile-porn.com, vous envoyez des nudes par SMS, vous vous rendez dans un sex shop, etc.
Et que donc toute personne, bien sous tout rapport, ne devrait avoir aucune crainte vis-à-vis d’un oeil inquisiteur sur ces activités (le fameux «moi j’ai rien à cacher»). A fortiori si cela permet d’arrêter les criminels.
C’est un peu moins trivial que cela.
Même le plus docte des mormons ferme la porte quand il va déféquer et tire le rideau quand il prend sa douche. C’est ça aussi l’intimité.
Également, la plupart des gens sont agacés quand ils reçoivent une publicité pour des poeles en inox après en avoir parlé le midi avec un ami.
Quand quelqu’un crée un deepfake pornographique d’une personne, cette dernière se sent généralement salie et particulièrement outrée que «son» image soit utilisée par des tiers à des fins lubriques.
Si, dans un avenir proche, vous receviez une notification de l’assurance maladie vous indiquant que votre cotisation va augmenter car vous êtes porteur d’un gène qui multiplie les chances d’infarctus ... vous ressentiriez probablement un sentiment d’injustice.
Pour le coup, c’est un des rares domaines où le monde politique est plus sensibilisé aux écueils que la société civile. Il y a en effet en France, une vraie tradition politique de méfiance vis-à-vis des dispositifs de fichage et de sanctuarisation de la confidentialité des correspondances.
La plupart des dispositifs ne sont autorisés qu’accompagnés de garde-fous. Ce qui semble plutôt raisonnable quand on mesure la fréquence à laquelle les fichages se font pirater et finissent vite dans la nature.
Ce qui est par contre mal mesuré par le public ET par le monde politique c’est le rapport coût / bénéfice de certaines mesures intrusives (on pourrait dire «pivaticides») quand elles ont pour objectifs annoncé d’attraper les pédophiles et les terroristes.
Parce que si arrêter des pédocriminels est plus important que notre intimité, alors nous devrions tous accepter d’avoir des caméras de surveillance chez nous 24h/24 dans toutes les pièces (car nombre de viols d’enfants ont lieu au domicile).
Or, d’une part, personne ne serait prêt à une telle concession et, d’autre part, si c’était mis en place, les pédocriminels accompliraient simplement leur méfait ailleurs.
Cet exemple un peu extrême n’est pas si loin de la réalité. Notamment quand on entend parler de permettre aux enquêteurs de déchiffrer les communications des principaux canaux (WhatsApp, SMS, ...). L’affaiblissement de l’intimité serait significatif alors qu’en face il serait facile pour les terroristes, d’utiliser un moyen de communication qui y échappe.
Et chaque fois qu’on propose de mettre une backdoor dans ces outils, pour permettre aux enquêteurs de les déchiffrer, on affaiblit la sécurité de ces outils. Car vous ne pouvez jamais avoir l’assurance, en cybersécurité, que vous serez le seul à pouvoir utiliser une backdoor. Par là même, on démultiplie les risques qu’un pirate puisse y accéder à la place des enquêteurs (avec toutes les conséquences que ça pourrait avoir).
Ça ne veut pas dire que ça ne vaut jamais le coup.
- il existe des dispositifs intrusifs où le bénéfice est réel (les criminels ne peuvent pas facilement se tourner vers une solution alternative)
- il existe des dispositifs intrusifs où le coût sur l’intimité est réduit
- il existe des dispositifs intrusifs où le risque de détournement de ce dispositif est faible.
Mais on a rarement vus des cas où ces 3 conditions sont réunies.
Donc si les experts en cybersécurité ont l’air de toujours pester contre les projets de lois invasifs en matière informatique, ce n’est pas QUE parce qu’ils sont issus de mouvances punk-anarchistes. C’est malheureusement que les solutions proposées sont souvent bancales et faillissent sur une ou plusieurs des 3 conditions.
OSINT
Kill chain
C'est la description des étapes d'une cyberattaque : d'abord l'attaquant effectue une reconnaissance de la cible, puis il s'y introduit, s'y propage, s'y rend persistant, et, à la toute fin, déclenche l'impact.
La kill chain d'attaque est avant tout une modélisation faite pour faciliter la compréhension des cyberattaques et normaliser le vocabulaire (c'est éducatif).
Il en a existé plusieurs variantes. Pratiquement toutes suivent le macro-modèle "Get In, Stay In and Act" (renter, rester, agir). La plus plébiscitée actuellement est celle du MITRE appelée ATT&CK.
Elle peut être résumée ainsi :
- Reconnaissance : l'attaquant cherche à glaner le plus d'informations possibles sur la cibles (notamment via l'OSINT) : où sont ses locaux, qui sont ses fournisseurs, qui sont ses clients, le nom des personnes qui y travaillent et leurs coordonnées, les sites et services Web qu'ils utilisent, etc.
- Acquisition des capacités offensives (weaponization) : maintenant que l'adversaire a cartographié toute la surface d'attaque de la cible, il va développer ou acheter des outils pour pénétrer cette surface (des 0 days avec exploit par exemple).
- Accès initial : c'est le premier moment d'interaction directe avec la cible, l'attaquant utilise ses moyens offensifs pour pénétrer dans le réseau de la cible (via un employé piégé avec du phishing, une intrusion physique en se faisant passer pour un prestataire, une 0 day contre un pare-feu, etc.)
- Installation / Persistance : l'attaquant va chercher à pérenniser son accès au réseau en installant une porte dérobée (backdoor), car la fenêtre de temps de son accès initial est souvent trop courte pour mener toute l'attaque. Il peut aussi s'aménager un accès secondaire de secours au cas où quelqu'un lui coupe son accès principal (si quelqu'un de l'entreprise ciblée détecte sa présence par exemple)
- Propagation : l'attaquant cherche à se répandre le plus profondément possible dans le réseau : infecter les autres utilisateurs, les autres postes, les bureaux des autres villes, etc. Son but est de maximiser l'étendue sur laquelle s'appliquera son action finale
- Impact : c'est là que l'attaquant accomplit son but : chiffrer les données, les exfiltrer, les détruire, couper les serveurs, demander une rançon, etc. C'est malheureusement souvent seulement lors de cette étape finale que la cible découvre qu'elle a été compromise.
Cette modélisation des attaques s'applique surtout aux APT. Les attaques plus communes sont aussi souvent plus directes (et ne s'embarrassent pas forcément d'être persistantes par exemple).
Cette modélisation est parfois critiquée pour son aspect très linéaire.
En effet, dans une attaque réelle, certaines phases sont susceptibles d'être menées dans une autre ordre, ou même en parallèle.
Essayer de détecter les attaques, en se focalisant trop sur ce modèle, peut laisser des trous dans la raquette.
Maintenant, voyons comment ce terme est généralement utilisé : « Les nombreux serveurs Windows non à jour ont été déterminants dans la kill chain de l'attaque subie » = l'attaquant s'est propagé très facilement dans le réseau à cause des nombreux serveurs non à jour, cela a fortement contribué à aggraver les conséquences de l'attaque (mais ce n'en est pas la cause, ni la seule étape).
Shadow IT
Le Shadow IT désigne toute l'informatique utilisée dans une structure, sans que l'équipe informatique ne le sache : Thierry qui utilise sa clé USB perso, le patron qui s'est mis une Box Orange dans son bureau pour pouvoir naviguer sans filtre, Camille qui branche son iPhone à son PC pro pour le recharger, le presta qui se connecte au WiFi avec un PC qui vient de son entreprise, ...
C'est donc différent du BYOD (Bring You Own Device) qui désigne le fait d'utiliser des équipements persos dans le cadre pro. Si vous avez synchronisé votre messagerie pro sur votre téléphone perso, c'est du BYOD. Mais ce n'est pas du Shadow IT si l'équipe informatique est au courant de cette pratique.
Inversement le Shadow IT peut concerner de l'informatique qui n'est pas perso : par exemple si le service marketing décide de créer un site promotionnel sur Wordpress sans en avertir le directeur informatique.
Le Shadow IT est avant tout une problématique d'angle mort.
En effet, dans un réseau, on ne peut sécuriser que ce qu'on connaît. Si des éléments échappent à la cartographie de l'équipe informatique, cette équipe ne pourra pas assurer leur sécurité. Cela décuple les chances de voir des failles y apparaître : absence de mises à jour, mot de passe simple, etc.
Or pour un attaquant, il suffit parfois d'un seul élément vulnérable connecté au réseau pour y faire des ravages (même si 99% du reste du parc est irréprochable).
Donc plus une entrepris grossit, plus il y a de monde, moins le directeur informatique peut avoir les yeux partout, plus il y a de chances qu'il y ait du Shadow IT
Supply chain attack
C'est le fait de se faire pirater par le biais d'un fournisseur.
Les cas les plus documentés ce sont via des fournisseurs de logiciels.
En effet, pour un cybercriminel c'est TRÈS rentable de pirater une éditeur de logiciel : vous le piratez UNE FOIS et ça vous permet de rentrer dans les réseaux de tous ses clients (potentiellement des millions).
L'exemple le plus éloquent est l'attaque NotPetya de 2017. Un éditeur de logiciel de comptabilité ukrainien avait été piraté. Les attaquants ont mis un virus dans la mise à jour la plus récente. Tous les clients se sont retrouvés piratés une fois qu'ils avaient installé cette mise à jour. Par rebond, toutes les multinationales, qui avaient des filiales en Ukraine qui utilisaient ce logiciel, ont été compromises aussi.
Saint-Gobain est touché (250 millions € de dégats). FedEx (300 millions $ de dégats), Nivea (35 millions €), ...
Pendant longtemps c'était un angle mort de la cybersécurité. Puis c'est devenu le moyen préféré des attaquants pour rentrer des les grands groupes (qui avaient atteint un niveau de sécurité prohibitif pour les pirates). Vous trouvez une petite start up qui a vendu son outil de Business Intelligence à une très grande banque, vous piratez cette start up et vous avez un pied dans le réseau de cette grande banque.
Depuis, les grands groupes ont des exigences de cybersécurité envers leurs prestataires, aussi petits soient-ils.
Leak (breach)
Log
Les logs (journaux en français) sont des événements, enregistrés par un système, permettant d’avoir une traçabilité de ce qu’il s’est passé sur ce système.
Ce n’est ni plus ni moins qu’un journal de bord où il est dûment inscrit «machin a fait ceci à telle heure tel jour».
Quand un événement a été enregistré sous forme de log, on dit que le système a loggé cet événement (ce n’est pas le même sens que «se logguer sur un site» qui signifie s’y authentifier).
Premièrement, qu’est-ce qui peut créer des logs ?
Ce peut être un système d’exploitation (votre Windows 11 enregistre tous les faits marquants et vous pouvez les visualiser dans l’outil «observateur d’événements»), une application, un site Web, etc.
J’ai parlé au sens large de «système» car c’est globalement n’importe quoi qui a une utilité à garder une traçabilité de ce qu’il se passe.
Maintenant, à quoi ça ressemble un log ?
Ça se présente, presque tout le temps, sous la forme d’un fichier texte où il y a une ligne par événement.
Ce qui est marqué sur cette ligne dépend de ce que le système qui log considère comme pertinent de savoir.
Ainsi, un log d’un serveur bancaire enregistrera probablement l’heure d’une transaction, son montant, son créditeur, son débiteur, son résultat (effectuée ou échouée), etc. Et il n’enregistrera probablement pas le signe astrologique du créditeur et la couleur préférée du débiteur.
Par exemple, voici à quoi pourraient ressembler un extrait des logs de Google :
203.0.113.45 [03/Nov/2025:14:22:31 +0000] "GET /search?q=outils+sécurité HTTP/1.1" 200 8421 "https://www.google.com/" "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/124.0.0.0 Safari/537.36"
198.51.100.12 [03/Nov/2025:14:22:33 +0000] "POST /login HTTP/1.1" 302 0 "https://accounts.google.com/signin/v2/identifier" "Mozilla/5.0 (Macintosh; Intel Mac OS X 13_6) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/16.6 Safari/605.1.15"
66.249.73.101 [03/Nov/2025:14:22:35 +0000] "GET /images/branding/googlelogo/2x/googlelogo_color_272x92dp.png HTTP/1.1" 304 0 "https://www.google.com/" "Mozilla/5.0 (compatible; Googlebot/2.1; +http://www.google.com/bot.html)"
192.0.2.77 [03/Nov/2025:14:22:38 +0000] "GET /maps/api/staticmap?center=Paris&zoom=12&size=600x300&key=YOUR_API_KEY HTTP/1.1" 200 12345 "https://maps.google.com/" "Mozilla/5.0 (Linux; Android 13; Pixel 7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/124.0.0.0 Mobile Safari/537.36"
203.0.113.89 [03/Nov/2025:14:22:41 +0000] "GET /mail/u/0/#inbox HTTP/1.1" 200 58732 "https://mail.google.com/" "Mozilla/5.0 (iPhone; CPU iPhone OS 17_0 like Mac OS X) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/17.0 Mobile/15E148 Safari/604.1" On peut voir 5 lignes, donc 5 événements (Google en a probablement plusieurs millions par seconde).
La première ligne indique qu’un visiteur ayant l’adresse IP 203.0.113.45 a émis une requête vers Google le 3 Novembre 2025 à 14:22 (heure de Greenwich). Plus précisément, ce visiteur a émis une requête vers l’URL « /search?q=outils+sécurité » qui correspond à une recherche Google portant sur les termes «outils» et «sécurité». On sait que Google lui a répondu avec succès (c’est la convention du «200» que l’on peut voir) une page de résultat qui faisait 8421 bits. Et on sait aussi que le visiteur se connectait avec un programme désigné comme «Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/124.0.0.0 Safari/537.36» ce qui est, croyez le ou non, la façon dont le navigateur Edge se présente aux sites Web visités.
Petite parenthèse terminologie. Ce que nous venons de faire, décortiquer ce log, se dit «parser un log». C’est-à-dire en extraire les informations brutes et les organiser/structurer. Le «parsing» est généralement réalisé automatiquement par un programme (un parseur) et non par des humains (ce serait trop long).
Pourquoi les logs sont importants ?
Premièrement pour l’investigation numérique !
Chaque fois qu’une entreprise se fait pirater, ou qu’une malversation est commise depuis un serveur, on va aller regarder ce qu’il s’est passé dans les logs pour comprendre comment c’est arrivé.
C’est aussi utilisé pour débugger des programmes.
Et là ce qui va être déterminant c’est la «rétention» des logs.
En effet, un système ne peut pas maintenir un journal de logs infini. Il manquerait de place. Donc les logs ont généralement une durée, ou une taille, de «rotation» au delà de laquelle ils sont «écrasés» par les nouvelles entrées.
Si après votre piratage on se rend compte que l’intrus est probablement rentré sur votre système il y a un mois, mais que vous avez seulement 1 semaine de rétention de logs ... on ne vas pas pouvoir observer comment il a fait.
Un pirate peut aussi tenter d’effacer les logs pour couvrir ses traces après un piratage.
Donc la première chose à retenir c’est que, souvent, on ne peut faire la lumière sur un événement en cybersécurité que s’il y a des logs à analyser. Donc disposer de logs suffisants est crucial en cybersécurité et c’est un chantier pas si trivial que ça à mettre en place.
Deuxième raison pour laquelle les logs sont importants : la meta-analyse.
Les logs sont en fait une mine d’or d’informations sous-jacentes, une fois qu’ils sont rassemblés et recoupés.
Reprenons notre exemple de Google et des informations que l’on avait extraites de la première ligne de log.
Si au lieu de parser seulement ce log, je parse les milliards de logs de Google, et que je range les informations dans une base de données, je vais pouvoir avoir des informations intéressantes.
Je pourrais interroger ma base de données en lui demandant «donne moi toutes les requêtes effectuées depuis l’adresse IP 203.0.113.45». Et il va me donner «/search?q=outils+sécurité» mais aussi toutes les autres requêtes de cet utilisateur :
- /search?q=restaurant+Blagnac
- /search?q=risque+faux+arret+de+travail
- /search?q=taches+rouges+sur+le+pénis
- /search?q=club+tennis+toulouse
- /search?q=rencontre+extraconjugale+31
- /search?q=Fillon+2027
- ...
Avec ces quelques exemple, vous voyez qu’on peut déjà se faire une idée assez précise des hobbies de cette personne, de ses opinions politiques, de son état de santé, de ses goûts, ...
Ça peut ensuite être utilisé pour du ciblage publicitaire, politique, pour de la surveillance, etc.
Autre demande que je peux faire à ma base de données contenant tous les logs de Google : « donne moi les requêtes effectuées, toutes IP confondues, triées par nombre d’occurrence, dont la date se trouve entre aujourd’hui et le 1 Janvier 2025 ».
Je vais alors me retrouver avec quelque chose comme ça :
- 10 220 654 : /search?q=sarkozy+prison
- 9 873 509 : /search?q=reconnaissance+palestine
- 8 031 397 : /search?q=démission+gouvernement
- ...
- 301 609 : /search?q=avion+comac
- ...
Cela permet de connaître les mots clés qui intéressent le plus les utilisateurs, mais également de voir venir des phénomènes émergents.
Bref l’idée globale est celle-ci : pris tout seul un log a peu de valeur. Agrégé à tous les autres, il révèle des informations inestimables.